들어가며
EMNLP((Empirical Methods in Natural Language Processing)는 ACL(Association for Computational Linguistics)과 함께 전산언어학 분야에서 가장 인지도가 있는 컨퍼런스 입니다. 그 중, 2018년도에 벨기에 브뤼셀에서 열린 EMNLP 2018 컨퍼런스에 다녀오게 되었습니다. ACL과 EMNLP의 논문 통계를 분석해보는 논문[1]이 나올 정도로 NLP에 있어서 두 컨퍼런스는 인지도가 높은 것 같다는 생각이 들었습니다.
해외 컨퍼런스 참석 경험은 이번이 두번째인데요, 처음은 2012년에 제주에서 열린 ACL에 참석하였습니다. 그때만 하더라도, 컨퍼런스 프로그램이 어떻게 구성되어있는지, 어떤 연구주제들을 주로 다루고 있는지 아무런 사전 준비 없이 참석을 하게 되었습니다. 듣고자 하는 세션이나 튜토리얼을 정하지 않은 채, 참석해보니 내용도 머리속에 잘 들어오지 않고, 어떤 점이 재미있는지 참신한지 와닿지가 않았던 경험이 있었습니다.
그때 경험을 생각해서 이번에는 좀더 철저하게 준비를 해야겠다는 생각이 들었습니다. 그래서 참관하기로 결정난 후, 컨퍼런스 사이트에 들어가서 발표될 논문들과 튜토리얼 / 워크샵을 살펴보고 미리 들어야할 내용대로 시간표를 작성하였습니다.
이번 컨퍼런스는 약 2500여명이 참여하고, 550여편의 논문, 그리고 14개의 워크샵과 6개의 튜토리얼, 3개의 키노트가 준비되었습니다. 작년과 비교해서 논문 편수도 30%이상 증가 했는데요, 3일동안 꽉꽉 채워서 발표 일정이 준비되어 있었습니다.
저는 현업에서 형태소 분석과, 개체명 인식 시스템을 연구/개발하고 있는 일을 하고 있는데요, 최근에 가장 관심있게 진행한 내용이다보니 이 분야에 대한 내용을 많이 들을려고 노력하였습니다.
워크샵 소개
이틀 동안 많은 튜토리얼과 워크샵이 동시에 진행되었습니다. 그중에서 가장 흥미를 끌었던 것은 “BlackboxNLP”라는 제목으로 개설된 워크샵이었습니다. 이 워크샵은 “Analyzing and interpreting neural networks for NLP”으로 설명이 되어있는데, NLP에서 사용되는 여러 뉴럴넷 기술들을 해석하고 그 의미를 파악해보고자 하는 것이 목표입니다.
보통, 뉴럴넷으로 학습된 모델은 그 과정은 알 수 없는 블랙박스라서, 왜 이렇게 결과가 나왔는지 알수 없는 경우가 대부분입니다. 그런데, 그 블랙박스를 탐구해보고자 만들어진 워크샵이라 흥미가 생겼습니다.
워크샵 첫날 invited talk에서는 RNN이 왜 시퀀스를 잘 표현하는지 그 내부를 이해해보고자 하는 내용으로 발표가 있었는데요[2], 6개의 질문을 던지고, 해당 질문에 대해 연구를 수행한 논문들을 소개하며 그 내용을 설명해 나가고 있었습니다. 그중 첫번째 질문은 아래와 같습니다.
Q1: What is encoded/captured in a vector?
RNN에 의해서 생성된 output vector가 실제로 담고 있는 정보가 무엇인지 그 내용을 파악해보고자 하는 시도입니다. 발표 초반에, NLP 학회에 제출했다가 리젝트 당했다는 에피피소드와 함께 소개해주었던 논문인데요[3]
이 논문에서는 sentence embedding vector가 문장을 얼마나 잘표현하는지에 대한 탐구를 한 논문입니다. 먼저 다음과 같이 문장을 벡터로 표현하는 두 가지 방법을 설명합니다.
CBOW : word2vec에서 사용하는 방법입니다. 이렇게 구한 word embedding을 각각 element에 대해서 average한 것을 sentence embedding으로 사용하는 방법입니다.
ED : Encoder-Decoder모델입니다. RNN은 LSTM을 사용하고, Encoder에서 마지막에 생성된 벡터를 sentence embedding으로 정의합니다.(auto encoder와 같이 입력과 출력을 똑같이 하는 seq2seq모델을 생각하시면 될 것 같습니다.)
위와 같이 생성된 두가지 sentence embedding에 대해서 아래 3가지 항목에 대해서 평가를 진행합니다.
length prediction task 문장의 길이를 적당한 구간을 갖는 8개의 bin으로 나눈 뒤, 해당 문장의 길이가 이 bin안에 속하는지 알아내는 작업입니다. 입력은 sentence embedding하나이고, 8개의 클래스 중 하나를 찾아내는 문제입니다.
work-contents task sentence embedding하나와 word embedding을 서로 붙여서 모델의 입력으로 사용합니다. 그 후 해당 word가 이 문장안에 속해 있는지, 없는지를 binary classification 문제로 정의합니다.
word-order task
sentence embedding하나와 word embedding 2개를 서로 붙여서 모델의 입력으로 사용합니다. 이 두 단어의 순서가 문장안에 있는 순서와 동일하면 1, 그렇지 않으면 0을 출력하는 binary classification문제로 정의합니다.
 푸른색이 ED모델이고, 붉은색이 CBOW모델입니다. 그리고 3개의 task에 대해 각각 세로축은 accuracy 가로축은 sentence embedding size입니다.
푸른색이 ED모델이고, 붉은색이 CBOW모델입니다. 그리고 3개의 task에 대해 각각 세로축은 accuracy 가로축은 sentence embedding size입니다.
논문을 보면 이결과에 대한 자세한 해석이 있지만, 대략적으로 단순 average 한 것 보다는 LSTM으로 모델링 한 것이 길이나, 단어 포함여부, 그리고 단어의 순서정보까지 잘 임베딩에 녹아 있다는 점을 이야기 하고 있습니다. 보통 sentence embedding이 문장을 얼마나 잘 표현하는지 측정하는 방법에 대해서는 고민해본적 없었는데요, 막연히 averaging 모델보다는 LSTM을 사용한 것이 더 잘나오겠지, 생각만 하고 있었는데, 이런 실험결과를 보고 나니 그런 부분에 대한 의문이 좀 해소가 된 것 같습니다.
그 다음으로는 LSTM과 GRU에 대한 내용을 다뤘습니다. 보통 GRU는 LSTM보다 게이트 수가 적어서 속도 측면에서 이득이 있다고 알고 있는데요, 실제 제가 사용해본 바로는 성능차이가 그렇게 크기 나지는 않았습니다. 또한 sequence labeling 문제에서 SOTA라고 알려진 모델로는 “Bi-LSTM CRF”입니다. 따라서 저도 개체명 인식 문제에 이 모델을 기본으로 사용하고 있고요, GRU와 비교해봐도 큰 차이는 없어서 LSTM을 사용하고 있었는데 이번발표에서 GRU와 LSTM의 성능차이를 비교한 내용이라 관심이 더 갔습니다.
정확히 말씀드리면, LSTM과 GRU를 포함하여 gated RNN과 classic RNN을 비교한 논문인데요[3], 발표에서는 RNN의 종류가 여러가지인데, 그렇다면 RNN모델 별로 시퀀스를 표현하는 능력은 어떤 차이가 있는지 밝혀보자는 내용입니다.
 단어 임베딩을 받아들여서 하나의 문장 임베딩을 생성하는 RNN모델이라고 했을 때, 입/출력이 같은 형식이라고 해서, 성능이 같을지, 의문을 제시하고 있습니다.
단어 임베딩을 받아들여서 하나의 문장 임베딩을 생성하는 RNN모델이라고 했을 때, 입/출력이 같은 형식이라고 해서, 성능이 같을지, 의문을 제시하고 있습니다.
이에대한 해답을 찾기 위한 과정으로 chomsky hierarchy에 나오는 type0 ~ 3 grammar를 이야기 하고 있습니다. type2 grammar를 예로 말씀드리면, 이 문법으로 인식되는 언어는 context-free language입니다. 예는 “aaabbb(n=3)”와 같이 anbn과 같은 시퀀스입니다. 이를 인식하는 오토마타는 pushdown automata입니다. 이와 같이 formal language에서는 type0이 가장 일반적이고 제약이 없으며, type3이 가장 제약이 많은 language입니다.
아이디어는 RNN을 automata와 같이 해당 formal language를 인식하는 모델로 생각하는 것입니다. “aaaabbbb”와 같은 문자열을 입력으로 주고, 가장 마지막 context vector에 대해 인식여부를 결정하는 linear layer를 두어서 binary classification문제로 정의하는 것입니다. 그러면 이 RNN은 pushdown automata와 같은 능력이 있는 것으로 볼 수 있습니다.
LSTM과 GRU에 대해서 anbn 샘플은 n=1000까지, 그리고 anbncn 샘플은 n=100까지 해당하는 샘플을 학습시킵니다. 이후, 임의의 1000개의 샘플을 생성해서 테스트를 했는데요, 테스트 시, n=200그리고 문자별로 랜덤하게 1,2개씩 증감하여 테스트 데이터를 생성합니다.
 LSTM이 GRU보다 인식 성능이 더 높게 나왔다고 결론을 내고 있습니다.
LSTM이 GRU보다 인식 성능이 더 높게 나왔다고 결론을 내고 있습니다.
GRU는 LSTM보다 gate 수가 더 적기 때문에 학습 속도면에서 이득이 있다고 흔히 알고 있을 것입니다. 그리고 성능은 task마다 차이가 있어서 절대적으로 어떤 모델이 더 좋다고 할 수는 없을 것입니다. 이번 발표를 통해서 그래도 “근본적으로 LSTM이 GRU보다는 시퀀스를 더 잘 표현하는 구나”라는 생각을 하게 되었습니다.
개체명 인식 논문 소개
현업에서 개체명 인식에 관한 연구를 진행하고 있어서, 이 분야에 대한 기대가 많이 있었습니다. 그래서 좋은 모델이 있는지, 혹시 어떤 새로운 방법론이 나왔는지 열심히 살펴보았는데요, 새로운 모델 구조를 제시하는 논문보다는, 적은양의 데이터를 극복하는 방법에 대한 연구가 있었습니다.[4]
이 논문은 NER task와 CWS(Chinese Word Segmentation) task를 동시에 학습합니다. NER 코퍼스(1350문장)는 상대적으로 적고, CWS코퍼스(86924문장)는 양이 많은데요, CWS의 코퍼스가 가지고 있는 단어 경계 정보를 NER에서 활용하도록 하여, NER성능을 개선했다는 내용입니다.
성능은 기존 모델 대비 f-score기준 5% 향상 되었네요.
 또한, 레이블 셋이 서로 다른 두 데이터 셋이 있다고 했을 때, 이 데이터 셋을 각각 학습하면 데이터가 적은 쪽은 성능이 낮게 나올 것입니다. 이런 경우, 한 셋의 양이 충분히 많을 때, 이를 이용하여 적은 셋의 성능을 올릴 수 있는 방법을 제안하고 있습니다.[5]
또한, 레이블 셋이 서로 다른 두 데이터 셋이 있다고 했을 때, 이 데이터 셋을 각각 학습하면 데이터가 적은 쪽은 성능이 낮게 나올 것입니다. 이런 경우, 한 셋의 양이 충분히 많을 때, 이를 이용하여 적은 셋의 성능을 올릴 수 있는 방법을 제안하고 있습니다.[5]
 레이블이 2개짜리인 셋과, 3개짜리인 셋 두개를 동시에 학습하는데, 레이블을 판단하는 CRF-layer만 나누어지고, 하위 bi-lstm layer와 embedding layer는 서로 공유하는 형태로 되어있습니다. 최상단에는 두 CRF-layer에서 태깅된 결과를 병합하는 merge-layer가 있습니다. 두 crf layer의 결과를 병합하는데, 만약 동일한 엔티티에 대해서 서로 다른 태깅 결과가 나왔다면, 발생확률을 이용하여 적절히 선택해주는 기능을 같이 수행하게 됩니다.
레이블이 2개짜리인 셋과, 3개짜리인 셋 두개를 동시에 학습하는데, 레이블을 판단하는 CRF-layer만 나누어지고, 하위 bi-lstm layer와 embedding layer는 서로 공유하는 형태로 되어있습니다. 최상단에는 두 CRF-layer에서 태깅된 결과를 병합하는 merge-layer가 있습니다. 두 crf layer의 결과를 병합하는데, 만약 동일한 엔티티에 대해서 서로 다른 태깅 결과가 나왔다면, 발생확률을 이용하여 적절히 선택해주는 기능을 같이 수행하게 됩니다.
위 두 논문 이외에도 많은 논문이 있었는데요, 대체적으로 개체명 인식 모델 자체의 연구 보다는, 데이터를 잘 활용하는 방법에 대한 연구가 많았습니다. 그리고 개체명 인식과 함께 많이 진행되는 연구가 개체간 관계를 밝히는 작업(entity relation)과 개체의 중의성을 해결하는 작업(entity linking)이 있습니다. 개체명 인식과 함께 관계를 밝히는 작업을 진행한 연구도 있었고요.[6] end-to-end로 entity linking을 연구한 결과도 있었습니다.[7] 이 논문은 포스터 발표였네요. #Best Paper Awards 학회 마지막날에는 키노트와 구두 발표 세션, 그리고 마지막에는 우수 논문 시상식 및 발표가 있었습니다. 모두 4편의 논문에 대해 시상이 있었고, 그중에서 SRL(Semantic Rule Labeling)에 대해 연구한 논문을 소개하겠습니다.[8]
서술어(용언)의 경우 문장 완성을 위해 필수적인 논항(명사/부사)를 요구합니다. SRL은 의미역을 미리 정해놓고 술어가 가지는 필수 논항에 대해서 어떤 의미역을 가지는지 밝히는 작업입니다.
아버지(행위주역)가 신문(피행위주역)을 읽으신다. “읽다”라는 용언은 주어와 목적어로 각각 “아버지”와 “신문”을 가지게 되고, 이 논항의 역할을 각각 행위주역과 피행위주역으로 태깅을 하게되는 것입니다. 행위주역은 동사가 행위를 표현할 경우 그 행위를 지배하는 논항이 갖는 의미역이고, 피행위주는 그 행위의 영향을 입는 논항이 갖게 되는 의미역입니다.
이 작업을 하기 위해서는 형태소 분석 / 문장분석 / 의미 중의성 해소 등 다양한 분석이 선행되어야 할만큼 매우 어려운 작업입니다. 하지만 이 논문은 multi-task learning을 통해서 위에 나열한 작업을 동시에 학습하고 최종적으로 SRL을 수행하게 됩니다. 그리고 2018년도에 진행된 기존 연구 대비 10% 정도 성능 향상을 이끌어 냈다고 합니다.
 Layer r / p / J 에서 사용하는 모델은 단순합니다. 각 단어들의 embedding에 multi-head attention을 적용하여 context정보가 포함된 embedding을 얻습니다. 그리고 최상단 feed-forward에서 각각 task에 맞는 label을 결정하는 형태로 진행됩니다.
Layer r / p / J 에서 사용하는 모델은 단순합니다. 각 단어들의 embedding에 multi-head attention을 적용하여 context정보가 포함된 embedding을 얻습니다. 그리고 최상단 feed-forward에서 각각 task에 맞는 label을 결정하는 형태로 진행됩니다.
multi-task learning을 통해 서로 성격이 다른 여러 task를 동시에 학습하는 경우 항상 제대로 될지 의문이 있었습니다. 이번 학회 참관을 하면서 관련 논문도 많이 발표되고, 성능 개선도 많이 이루어졌다는 연구를 보니, 이 부분도 많이 일반화된 기술이 되어가는 것 같은 느낌을 받았습니다.
마치며
제 주관적인 느낌일 수는 있겠지만, multi-task learning, transfer learning을 이용한 논문이 유독 눈에 많이 들어왔습니다. 특히, 중국쪽에서 논문발표가 매우 많았는데요, 영어권에 있는 풍부한 코퍼스를 transfer learning을 통해서 중국어 버전의 시스템 성능향상에 기여를 했다는 논문도 나왔습니다. multi-task learning에 대해서는 좀 회의적인 느낌이 있었는데, best paper에 선정된 논문을 포함해서 여기저기 성과가 난다고 이야기 하고 있으니, 한번 시도해 볼만한 방법이지 않나 하는 느낌이 들었습니다.
100% 영어로 진행되는 모든 내용을 다 이해하고 돌아온 것은 아니지만, 더 넓은 범위에서 연구자들이 자기 연구결과를 발표하고, 또 질문하고, 답변하고, 때로는 서로를 칭찬해주기도 하고, 그런 현장을 경험 하고 왔다는 것이 가장 크게 남는 것 같습니다. 그리고 많은 자극도 되었구요.
또한, 학회 마지막날 전에 마련된 소셜 이벤트에서 스스럼 없이 서로 이야기 하면서 의견을 주고 받는 모습이 매우 인상적이었습니다. 저 또한 우연히 일본에서 유학중인 한국인 학생과 이야기할 기회가 있었는데, 일본 대학교에서의 연구실 분위기, 연구 관심분야 등등 이런 부분에 대해서 이야기를 나누었습니다. 만약, 영어로 의사소통이 가능한 상황이라면, 이런 경험을 더 많이 할 수 있었을 텐데.. 하는 아쉬움이 남았습니다.
해외학회를, 해외에서 직접 참관해본 것은 처음 이었습니다. 여러 학교/회사들의 연구자들의 결과물을 살펴보면서 보낸 5일은 정말 유익한 시간이었습니다.
레퍼런스
[1] EMNLP versus ACL: Analyzing NLP Research Over Time - pdf
[2] Trying to Understand Recurrent Neural Networks for Language Processing - silde
[3] FINE-GRAINED ANALYSIS OF SENTENCE EMBEDDINGS USING AUXILIARY PREDICTION TASKS - pdf
[3] On the Practical Computational Power of Finite Precision RNNs for Language Recognition - pdf
[4] Adversarial Transfer Learning for Chinese Named Entity Recognition with Self-Attention Mechanism - pdf
[5] Marginal Likelihood Training of BiLSTM-CRF for Biomedical Named Entity Recognition from Disjoint Label Sets - pdf
[6] Adversarial training for multi-context joint entity and relation extraction - pdf
[7] End-to-End Neural Entity Linking - pdf
[8] Linguistically-Informed Self-Attention for Semantic Role Labeling - pdf - video
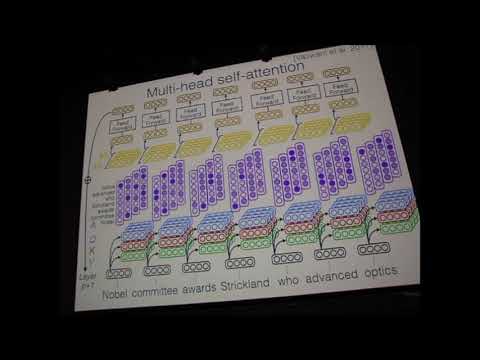 LISA 모델 설명 동영상
LISA 모델 설명 동영상